文章详情页 您现在的位置是:网站首页>文章详情
git仓库的大文件处理
 Jeyrce.Lu
发表于:2021年4月1日 22:02
分类:【服务器】
3516次阅读
Jeyrce.Lu
发表于:2021年4月1日 22:02
分类:【服务器】
3516次阅读
在中大型项目安装部署过程中,我们一定会面临将多个服务进行集成,最后生成一整套构建、部署的问题,大文件的处理方法是一件比较头疼的事情。一般有这样一些处理方法
(1)在打包时实时构建,大致需要经历:拉取代码 → 准备构建环境 → 构建可执行文件或链接库。
(2)将大文件存放在git仓库中,每次代码开发完成build一个二进制文件和代码存放在一起。实际上git官方也提供了git-lfs用来解决这个问题,但体验了一下并不好用。
(3)将大文件存放在文件服务器,打包时从文件服务器拉取。实际上和git-lfs的道理是相通的。
在以上方法中,(1)缺点其一是打包平台需要准备好构建环境,可能需要一些依赖问题;其二是项目构建时间可能会比较长,相邻打包行为之间的一些资源无法有效利用。(2)缺点在于git的提交机制将会对数据全量备份副本,而二进制文件的压缩比又非常低,提交量上来之后一个仓库马上会变得十分巨大,同步仓库速度越来越慢,浪费大量空间。方案(3)则是一种更为合适的方式,本文主要介绍通过 `nextcloud` 私有云盘+代码仓库链接记录的最佳实践。
硬件准备
- 3.6 T SATA 盘一块
- 740大盘托架
- DELL440服务器一台
(1)加载磁盘
磁盘插入插槽等亮起之后,我们可以通过qdatamgr media show 查看到磁盘,但是它处于热备状态 `Unconfigured(good), Spun Up ` 并不能直接使用,需要attach一下
qdatamgr media attach_disk -s P0B00S01 # 执行后将看到磁盘状态变为 Online, SPun Up # 此时通过lsblk也能查看到多了一块 sde盘,划分了sde1、sde2、sde3三个分区
(2)创建pv、vg、lv
# 在sde3分区上创建一个pv pvcreate /dev/sde3 # 在pv上划出一个名叫Mirrors的vg vgcreate Mirrors /dev/sde3 # 在Mirrors这个vg上占用所有空余空间创建一个名叫mirrors的lv lvcreate -n mirrors -l 100%FREE Mirrors
(3)将lv挂载到专用目录
# vim /etc/fstable 在文件末尾追加 # mirrors 挂载 /dev/mapper/Mirrors-mirrors /mirrors ext4 defaults 0 0 # 尝试挂载发现文件系统类型不对 mount -a #mount -a mount: wrong fs type, bad option, bad superblock on /dev/mapper/Mirrors-mirrors, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so. # 格式化lv的文件系统 mkfs -t ext4 /dev/mapper/Mirrors-mirrors # 重新moun,成功 mount -a # 已经可以在df中查看到挂载点 df -h # /dev/mapper/Mirrors-mirrors 3.6T 89M 3.4T 1% /mirrors
安装nextcloud
(1)安装docker、docker-compose(略)
(2)安装配置nextcloud
# 拉取最新镜像 docker pull nextcloud # 编写docker-compose.yml #cat docker-compose.yml version: '2.3' services: nextcloud: image: nextcloud container_name: nextcloud restart: always volumes: - /mirrors/tmp:/tmp - /mirrors/file:/var/www/html dns_search: . logging: driver: json-file options: max-size: 20M max-file: "20" ports: - 9090:80 # 启动服务 docker-compose -f docker-compose.yml up -d
(3)初始化
此时打开浏览器查看9090端口发现已经可以看到初始化页面了,创建一个管理员账户即可开始使用。
注意其中支持sqlite、mysql、postgree三种数据库,在docker内部访问mysql需要特殊设置,因此直接使用sqlite。
文件的上传下载
(1)上传
使用上面(3)中创建的用户登录nextcloud后,可以在用户目录下创建文件夹或上传文件,也可直接拖动文件到页面上。

(2)下载
在nextcloud页面上,我们可以通过下载按钮,或者通过分享来提供一个下载地址,但是通过这样的接口功能来下载,我们需要构造携带有身份信息的请求。而为了更方便的下载,我们可以直接将文件目录挂载到nginx的autoindex索引。
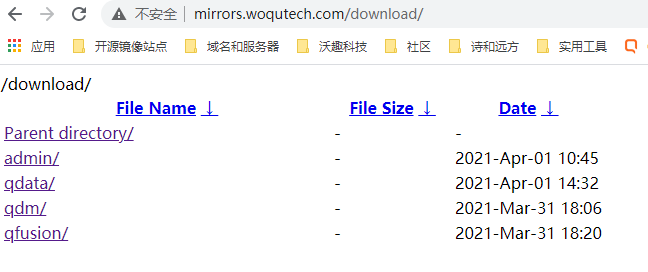
# 忽略一些干扰文件的索引
fancyindex_ignore nextcloud.db;
fancyindex_ignore nextcloud.log;
fancyindex_ignore index.html.default;
fancyindex_ignore appdata_oce746a3ysjj;
fancyindex_ignore files_external;
fancyindex_ignore cache;
fancyindex_ignore files_trashbin;
fancyindex_ignore Talk;
fancyindex_ignore Documents;
fancyindex_ignore Nextcloud Manual.pdf;
fancyindex_ignore Nextcloud intro.mp4;
fancyindex_ignore Nextcloud.png;
fancyindex_ignore Photos;
fancyindex_ignore Reasons to use Nextcloud.pdf;
include fancyindex.conf;
# nginx 文件目录索引
location /download {
alias /mirrors/file/data/;
charset utf-8;
autoindex on;
autoindex_exact_size off;
autoindex_localtime on;
}(3)引用方法
我们在仓库中并不保存二进制文件本身,而是保留一个名为 {文件名}.link 的文本文件,文本内容简单的记录了二进制文件的下载链接。此外提供了一个nextcloud.sh的shell脚本,用于递归找到当前目录下所有.link文件,并从链接恢复为去除.link后缀的文件。
jeeyshe@jeeyshe-PC:~/Code/go/src/xoo.site/ido.go/file$ tree . ├── bin │ ├── prometheus.link │ └── test │ └── alertmanager.link ├── nextcloud.sh ├── phoenix.link └── write.go 2 directories, 5 files # 其中 .link 文件的内容如下所示 http://mirrors.woqutech.com/download/qdata/files/bin/phoenix/phoenix-1.3.0-test-x86
nextcloud.sh脚本
#!/usr/bin/env bash
# Created by Jeyrce.Lu 2021-04-01 14:01
force=false # 是否覆盖本地文件
clean=false # 是否清理.link文件
count=0
while getopts :fc x; do
case $x in
f)
# echo "恢复时强制覆盖本地文件"
force=true
;;
c)
# echo "恢复完成后清理.link文件"
clean=true
;;
*)
break
;;
esac
done
function lookupFile {
file=$1
force=$2
clean=$3
if test -f ${file}; then
if [[ $file == *.link ]]; then
target=${file%.link}
if ([ ! -f $target ] && [ ! -d $target ]) || [ "$force" = true ]; then
# 从文件服务器拉取恢复为大文件
echo [${target##*/}] "从远端恢复文件"
wget -i $file -O $target --timeout 60 > /dev/null 2>&1
let count++
else
echo [${target##*/}] "文件(夹)已存在"
fi
if [ "$clean" = true ]; then
echo [${file##*/}] "将被清理"
rm -f $file
fi
fi
elif test -d ${file}; then
for subfile in $1/*; do
lookupFile ${subfile} ${force} ${clean} #递归遍历
done
fi
}
lookupFile `pwd` ${force} ${clean}
echo $count "条记录已恢复"
exit 0使用示例:
# 自动查找项目下所有 .link 文件并尝试从远端恢复
# 如果本地已经存在 {name}.link 对应的{name}文件或文件夹,则不从远端恢复
# 恢复完成后保留 .link 文件
bash nextcloud.sh
# 无论本地是否已存在,都从远端获取文件覆盖本地
bash nextcloud.sh -f
# 从远端恢复完大文件后,删除对应的.link
bash nextclou.sh -c我们执行nextcloud.sh脚本之后,可以成功获取对应的大文件。后续还可以添加一下例如校验md5值,恢复文件后修改权限等功能(当前恢复出来的文件会丢失rwx权限,需要在正式部署某一步骤赋予权限)。
版权声明 本文属于本站 原创作品,文章版权归本站及作者所有,请尊重作者的创作成果,转载、引用自觉附上本文永久地址: http://blog.lujianxin.com/x/art/4i8smdx9ijyi
下一篇:git仓库的大文件处理
猜你喜欢
文章评论区
作者名片
- 作者昵称:Jeyrce.Lu
- 原创文章:61篇
- 转载文章:3篇
- 加入本站:2342天
作者其他文章

站长推荐
友情链接
站点信息
- 运行天数:2343天
- 累计访问:164169人次
- 今日访问:0人次
- 原创文章:69篇
- 转载文章:4篇
- 微信公众号:第一时间获取更新信息
