文章详情页 您现在的位置是:网站首页>文章详情
prometheus配置文件详解
 Jeyrce.Lu
发表于:2021年6月19日 17:13
分类:【服务器】
5944次阅读
Jeyrce.Lu
发表于:2021年6月19日 17:13
分类:【服务器】
5944次阅读
prometheus是整个监控告警架构的核心服务,而promehteus的定时拉取任务、存储、告警触发、推送等行为过程由启动时命令行参数和一份yml格式的文件描述。命令行参数涵盖范围是有限并且启动后是固定不变的,而yml文件则可以根据业务逻辑进行组织并进行热加载。本文针对prometheus配置文件的所有语法进行详细解释,必要时会结合一些实例进行阐释。
本文阐述基于2.24.1版本,其他版本可能略有差异。
命令行参数
--config.file 即指定上文yml文件位置,默认为当前目录下 prometheus.yml
--web.listen-adress 指定监听地址和端口,默认为 "0.0.0.0:9090"
--web.config.file 用于开启TLS或者认证
--web.read-timeout prometheus管理页面访问超时,支持 5s, 5m 这样的单位配置
--web.max-connection 最大同时连接数限制
--web.external-url 额外的url格式,例如我们可以为prometheus的api加上前缀
--web.route-prrfix 同 erternal-url一样可以控制前缀,之后可能会移除这个参数
--web.user-assets 用户静态文件目录,我们可以通过这个配置自定义prometheus的默认ui
--web.enable-lifecycle 启用热加载api,关于热加载以下会单独介绍
--web.enable-admin-api 启用后可以通过api来对prometheus进行查询和管理
--web.console.templates 指定控制台页面模板,用于自定义ui
--web.console.libraries 自定义控制台所需要的库文件
--web.page-title 自定义页面的tile标签
--web.core.origin 请求头跨域指定,默认为 ".*"
--storage.tsdb.path 监控数据存储目录,默认为工作目录下 data/
--storage.tsdb.retention 监控数据持久化存储保持时间,这个flag即将废弃,建议使用–storage.tsdb.retention.time
--storage.tsdb.retention.time 作用同retention,推荐的参数,可以使用 90d 这样的格式
--storage.tsdb.retention.size 【实验性功能】按照数据文件大小保留持久化数据
--storage.stdb.no-lockfile 不创建数据文件的lockfile,可以节省磁盘空间但是增加了数据块损坏的风险
--storage.tsdb.allow-overlappping-block 【实验性功能】启用数据垂直压缩
--storage.tsdb.wal-compression 启用wal文件的压缩
--storage.remote.flush-deadline 配置远程写数据以及配置重载最大时间,详见prometheus远程读写
--storage.remote.read-sample-limit 远程读取样本点最大数量,默认为五千万
--storage.remote.read-concurrent-limit 并发远程读的线程数限制,0代表不限制
--storage.remote.read-max-bytes-in-frame 单个查询框中样本数据大小限制,默认为protobuf本身限制
--rules.alert.for-outage-tolerance 允许告警规则中“持续检测时间”最大值,默认为1h
--rules.alert.for-grace-period 告警触发和解决与 "for" 状态之间最短持续时间,只对配置了 for 的告警有效,默认为10m
--rules.alert.resend-delay 触发的告警持续发送给alertmanager的最小等待时间
--alertmanager.notification-queue-capacity 将要推送给alertmanager的告警队列大小限制,默认为1万
--alertmanager.timeout 推送给alertmanager消息的超时时间,支持 1m 格式配置,默认为 10s
--query.max-concurrency 并发查询数量限制,默认为20
--query.timeout 单次查询的超时时间,默认为2m
--query.max-samples 单次查询的最大样本点数量,默认为五千万
配置热加载
当修改了配置文件后,无需重启proemtheus服务也可读入新的配置进行job、instance的任务重新分配,提供了两种方式来重载配置。实际上这是一种成熟的热加载方式,在一些exporter中也采用了此方式来重载配置,而phoenix本身亦是提供了类似的机制。
(1)SIGHUP信号
[root@192-168-1-99 ~]# pgrep prometheus 1805 [root@192-168-1-99 ~]# kill -HUP 1805
(2)调用重载api
# 使用此方法有一个前提是: 启动prometheus的时候需要启用 --web.enable-lifecycle curl -X POST "http://127.0.0.1:10011/prometheus/-/reload"
配置文件语法
全局配置
# 全局配置, 通常可以被job单独的配置覆盖 global: # target 定时任务周期 scrape_interval: 1m # 拉取指标超时 scrape_timeout: 10s # 执行 rules 规则的时间 evaluation_interval: 30s # 额外添加给所有时序数据、告警的标签 external_labels: product: qdm # 使用PromQL查询的日志,每次重载都会重新打开 # query_log_file: ""
告警规则
通常来讲告警规则文件和主配置文件分离,会被业务端按照实际所需进行修改,而主文件定义后则一直处于固定状态。
# 告警规则文件,定义告警触发规则,由一组rule文件组成 rule_files: - "rules.yml"
远程读写配置
此部分内容需参考prometheus集群和高可用部分,如果是单机架构则无需配置。
remote_write: - url: http://remote1/push name: drop_expensive write_relabel_configs: - source_labels: [__name__] regex: expensive.* action: drop - url: http://remote2/push name: rw_tls tls_config: cert_file: valid_cert_file key_file: valid_key_file remote_read: - url: http://remote1/read read_recent: true name: default - url: http://remote3/read read_recent: false name: read_special required_matchers: job: special tls_config: cert_file: valid_cert_file key_file: valid_key_file
告警配置
proemtheus将会通过rules对获取到的指标进行定时告警触发,并将触发的告警推送给下游进一步处理,一般我们选择alertmanager作为处理工具。
# 告警相关配置,用于将prometheus触发的告警推送给下游组件做进一步处理
alerting:
# 告警标签动态重组,用于更加灵活的控制alert属性
alert_relabel_configs:
- source_labels:
- product_type
- ip
separator: ;
regex: (.*);(.*)
target_label: routing_key
replacement: ${1}__${2}
action: replace
- source_labels:
- tid
- exporter
separator: ;
regex: (.*);oracle
target_label: routing_key
replacement: ${1}oracle
action: replace
# alertmanager配置,定义推送目标规则
alertmanagers:
- scheme: http
path_prefix: /alertmanager
timeout: 10s
api_version: v1
basic_auth:
username: admin
password: admin
static_configs:
- targets:
- "127.0.0.1:80"在以上配置中,我们通过relabel的方式生成了alertmanager中routing_key,通过prometheus的控制台我们可以发现当告警在prometheus中触发的时候还没有routing_key战歌label,但是当alertmanager接收到告警时已经携带了这个label,之后我们就可以通过这个routing_key来进行分组(关于分组机制,需参考: 告警组件Alertmanager)。

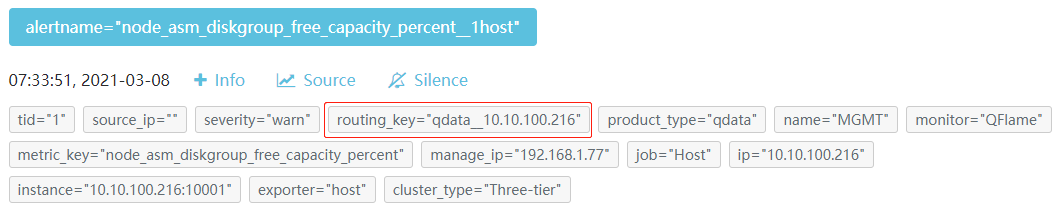
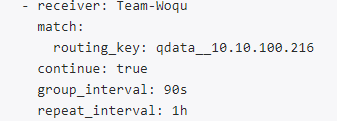
关于relabel,是一种动态匹配标签并进行修改的机制,需要参考: prometheus中的relabel机制。
监控对象发现
prometheus使用pull模式从各个exporter获取指标,然后对指标进行relabel、压缩、存储、通过rule规则进行告警触发等,scrape_configs块有由一组job组成,一组job又包含了若干target实例,这样一组数据描述了拉取指标的周期任务。
# 拉取指标的周期任务配置 scrape_configs: # job 名称 - job_name: prometheus # target实例数量限制,0代表无限制 target_limit: 7 # 请求方式 scheme: http # 一种服务发现机制,此处是最为简单的静态配置 static_configs: - targets: - 127.0.0.1:80 # 获取指标的path metrics_path: /prometheus/metrics
以上是prometheus本身暴露的一个指标端点,我们可以通过在配置文件中静态罗列的方式来定义一个job,而对于更为复杂的业务系统以及exporter采集端,我们还可以使用基于文件、k8s、api、docker_swam等等服务发现方式,详见篇章: prometheus服务发现机制。
版权声明 本文属于本站 原创作品,文章版权归本站及作者所有,请尊重作者的创作成果,转载、引用自觉附上本文永久地址: http://blog.lujianxin.com/x/art/5nwaai09dlc4
上一篇:Golang编码规范
下一篇:prometheus配置文件详解
猜你喜欢
文章评论区
作者名片
- 作者昵称:Jeyrce.Lu
- 原创文章:61篇
- 转载文章:3篇
- 加入本站:2493天
作者其他文章

站长推荐
友情链接
站点信息
- 运行天数:2494天
- 累计访问:164169人次
- 今日访问:0人次
- 原创文章:69篇
- 转载文章:4篇
- 微信公众号:第一时间获取更新信息
