文章详情页 您现在的位置是:网站首页>文章详情
消息队列进阶篇(一)
 Jeyrce.Lu
发表于:2019年12月29日 21:25
分类:【服务器】
2734次阅读
Jeyrce.Lu
发表于:2019年12月29日 21:25
分类:【服务器】
2734次阅读
内存中的堆栈和数据结构的堆栈
内存中的堆栈
内存空间在逻辑上分为三部分:代码区、静态数据区和文字常量区,动态数据区又分为栈区和堆区。
代码区:存储方法体的二进制代码。高级调度(作业调度)、中级调度(内存调度)、低级调度(进程调度)控制代码区执行代码的切换。
文字常量区
一般我们这样定义一个字符串时,其是在文字常量区的:
char* s1 = "hello, world";
char* s2 = "hello, world";
if(s1 == s2)
printf("s1和s2指向同一个在文字常量区的字符串");静态数据区:存储全局变量、静态变量、常量,常量包括final修饰的常量和String常量。系统自动分配和回收。
栈区:存储运行方法的形参、局部变量、返回值。由系统自动分配和回收。
例如 int method(int a){int b;}栈中存储参数a、局部变量b、返回值temp。
堆区:new一个对象的引用或地址存储在栈区,指向该对象存储在堆区中的真实数据。由程序员分配和回收(Java中由JVM虚拟机的垃圾回收机制自动回收)。
例如 Class Student{int num; int age;} main方法中Student stu = new Student();分配堆区空间中存储的该对象的num、age,变量stu存储在栈中,里面的值是对应堆区空间的引用或地址。
数据结构中的堆栈
栈:是一种连续存储的数据结构,特点是存储的数据先进后出。
堆:是一棵完全二叉树结构,特点是父节点的值大于(小于)两个子节点的值(分别称为大顶堆和小顶堆)。它常用于管理算法执行过程中的信息,应用场景包括堆排序,优先队列等
JMQ的Broker如何异步处理消息
首先,生产者发送一批消息给 Broker 的主节点;
Broker 收到消息之后,会对消息做一系列的解析、检查等处理;
然后,把消息复制给所有的 Broker 从节点,并且需要把消息写入到磁盘中;
主节点收到大多数从节点的复制成功确认后,给生产者回响应告知消息发送成功。
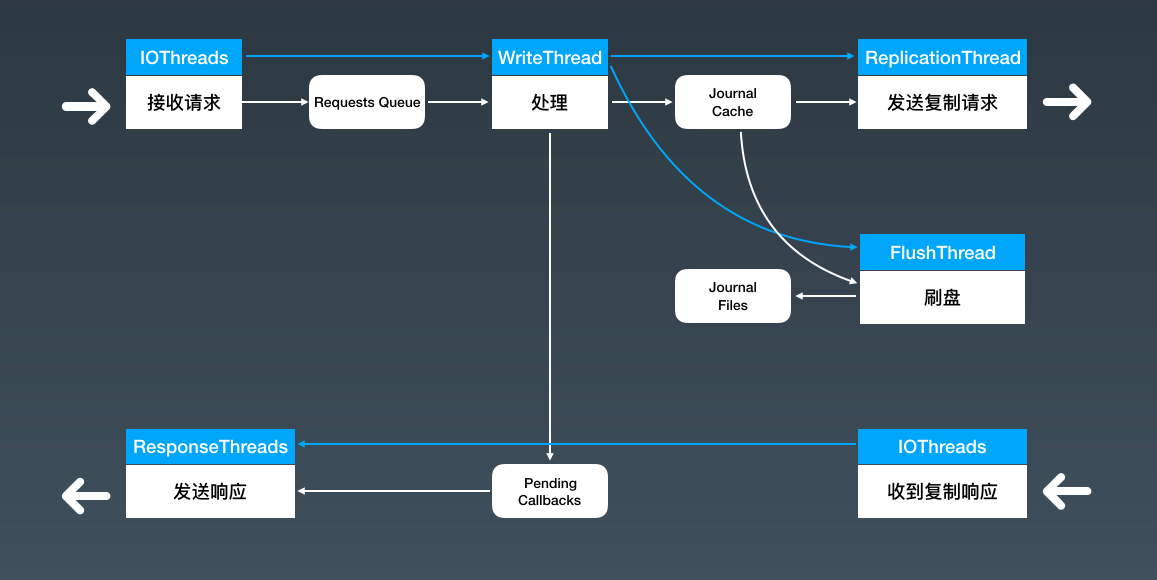
IOThreads只负责简单的接收请求, 然后就将请求信息放入队列中
WriteThread负责数据的序列化和解析,将数据写入JournalCache
执行到这里,一条一条的消息已经被转换成一个连续的字节流,每一条消息都在这个字节流中有一个全局唯一起止位置,也就是这条消息的 Offset。后续的处理就不用关心字节流中的内容了,只要确保这个字节流能快速正确的被保存和复制就可以了。
在这一步本应该给生产者响应,但是没有落盘数据持久化,所以把返回的响应放在内存链表Pending Callbacks中,并记录每个请求中的消息对应的Offset。
FlushThread 刷盘线程不断将写入JournalCache的字节流刷到磁盘上,完成一批数据的刷盘,它就会更新一个刷盘位置的内存变量,确保这个刷盘位置之前数据都已经安全的写入磁盘中
ReplicationThread 复制线程逻辑类似,同样维护了一个复制位置的内存变量
ReponseThreads 在刷盘位置或者复制位置更新后,去检查待返回的响应链表 Pending Callbacks根据 QOS 级别的设置(因为不同 QOS 基本对发送成功的定义不一样,有的设置需要消息写入磁盘才算成功,有的需要复制完成才算成功)将刷盘位置或者复制位置之前所有响应,以及已经超时的响应,利用这组线程 ReponseThreads 异步并行的发送给各个客户端。
JournalCache 的加载和卸载需要对文件加锁以外,没有用到其他的锁
Kafka如何实现高性能IO
使用批量消息提升服务端处理能力
kafka的发送端 Producer 只提供了单条发送的send方法,并没有提供任何批量发送的接口,原因是,Kafka 根本就没有提供单条发送的功能,虽然它提供的 API 每次只能发送一条
在kafka-python文档
send() is asynchronous. When called it adds the record to a buffer of pending record sends and immediately returns. This allows the producer to batch together individual records for efficiency. The ‘acks’ config controls the criteria under which requests are considered complete. The “all” setting will result in blocking on the full commit of the record, the slowest but most durable setting. If the request fails, the producer can automatically retry, unless ‘retries’ is configured to 0. Enabling retries also opens up the possibility of duplicates (see the documentation on message delivery semantics for details: https://kafka.apache.org/documentation.html#semantics ). The producer maintains buffers of unsent records for each partition. These buffers are of a size specified by the ‘batch_size’ config. Making this larger can result in more batching, but requires more memory (since we will generally have one of these buffers for each active partition). By default a buffer is available to send immediately even if there is additional unused space in the buffer. However if you want to reduce the number of requests you can set ‘linger_ms’ to something greater than 0. This will instruct the producer to wait up to that number of milliseconds before sending a request in hope that more records will arrive to fill up the same batch. This is analogous to Nagle’s algorithm in TCP. Note that records that arrive close together in time will generally batch together even with linger_ms=0 so under heavy load batching will occur regardless of the linger configuration; however setting this to something larger than 0 can lead to fewer, more efficient requests when not under maximal load at the cost of a small amount of latency. The buffer_memory controls the total amount of memory available to the producer for buffering. If records are sent faster than they can be transmitted to the server then this buffer space will be exhausted. When the buffer space is exhausted additional send calls will block.
在服务端,Kafka 不会把一批
构建批
kafka缓存策略
上文提到的PageCache,它就是一个非常典型的读写缓存。操作系统会利用系统空闲的物理内存来给文件读写做缓存,这个缓存叫做 PageCache。应用程序在写文件的时候,操作系统会先把数据写入到 PageCache 中,数据在成功写到 PageCache 之后,对于用户代码来说,写入就结束了。
在数据写到 PageCache 中后,它并不是同时就写到磁盘上了,这中间是有一个延迟的。操作系统可以保证,即使是应用程序意外退出了,操作系统也会把这部分数据同步到磁盘上。但是,如果服务器突然掉电了,这部分数据就丢失了
`读写缓存的这种设计,它天然就是不可靠的,是一种牺牲数据一致性换取性能的设计`
Kafka 它并不是只靠磁盘来保证数据的可靠性,它更依赖的是,在不同节点上的多副本来解决数据可靠性问题,这样即使某个服务器掉电丢失一部分文件内容,它也可以从其他节点上找到正确的数据,不会丢消息。
缓存数据的新鲜
那选择什么时候来更新缓存中的数据呢?比较自然的想法是,我在更新磁盘中数据的同时,更新一下缓存中的数据不就可以了?这个想法是没有任何问题的,缓存中的数据会一直保持最新。但是,在并发的环境中,实现起来还是不太容易的
是选择同步还是异步来更新缓存呢?
如果是同步更新,更新磁盘成功了,但是更新缓存失败了,你是不是要反复重试来保证更新成功?如果多次重试都失败,那这次更新是算成功还是失败呢?
如果是异步更新缓存,怎么保证更新的时序?比如,我先把一个文件中的某个数据设置成 0,然后又设为 1,这个时候文件中的数据肯定是 1,但是缓存中的数据可不一定就是 1 了。因为把缓存中的数据更新为 0,和更新为 1 是两个并发的异步操作,不一定谁会先执行。
另外一种比较简单的方法就是,定时将磁盘上的数据同步到缓存中。一般的情况下,每次同步时直接全量更新就可以了,因为是在异步的线程中更新数据,同步的速度即使慢一些也不是什么大问题。如果缓存的数据太大,更新速度慢到无法接受,也可以选择增量更新,每次只更新从上次缓存同步至今这段时间内变化的数据,代价是实现起来会稍微有些复杂。
如果说,某次同步过程中发生了错误,等到下一个同步周期也会自动把数据纠正过来。这种定时同步缓存的方法,缺点是缓存更新不那么及时,优点是实现起来非常简单,鲁棒性非常好。
还有一种更简单的方法,我们从来不去更新缓存中的数据,而是给缓存中的每条数据设置一个比较短的过期时间,数据过期以后即使它还存在缓存中,我们也认为它不再有效,需要从磁盘上再次加载这条数据,这样就变相地实现了数据更新
缓存置换策略
当应用程序要访问某些数据的时候,如果这些数据在缓存中,那直接访问缓存中的数据就可以了,这次访问的速度是很快的,这种情况我们称为一次缓存命中;如果这些数据不在缓存中,那只能去磁盘中访问数据,就会比较慢。这种情况我们称为“缓存穿透”。显然,缓存的命中率越高,应用程序的总体性能就越好。
一般来说,我们都会在数据首次被访问的时候,顺便把这条数据放到缓存中。随着访问的数据越来越多,总有把缓存占满的时刻,这个时候就需要把缓存中的一些数据删除掉,以便存放新的数据,这个过程称为缓存置换
到这里,问题就变成了:当缓存满了的时候,删除哪些数据,才能会使缓存的命中率更高一些,也就是采用什么置换策略的问题
命中率最高的置换策略,一定是根据你的业务逻辑,定制化的策略。比如,你如果知道某些数据已经删除了,永远不会再被访问到,那优先置换这些数据肯定是没问题的。
另外一个选择,就是使用通用的置换算法。一个最经典也是最实用的算法就是 LRU 算法,也叫最近最少使用算法
什么是pagecache
说到pagecache有几个关键词
sector(扇区): 文件存储在硬盘上, 硬盘最小单位叫扇区,每个扇区512字节,操作系统读取硬盘时会一次性读取多个扇区,即一次读一个块(block)
block(块): 这种由多个扇区组成的块是文件存取的最小单位,块的大小,最常见的是4KB,即连续八个sector组成一个block,文件数据都储存在块中,文件数据都储存在块中
inode(索引节点 index node): 很明显,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创年日期、文件的大小等等,这种储存元信息的区域叫做inode,中文译名为”索引节点”。inode (index node) 表中包含文件系统的所有文件列表。
在服务端,Kafka 不会把一批消息再还原成多条消息,再一条一条地处理,这样太慢了。Kafka 这块儿处理的非常聪明,每批消息都会被当做一个“批消息”来处理。也就是说,`在 Broker 整个处理流程中,无论是写入磁盘、从磁盘读出来、还是复制到其他副本这些流程中,批消息都不会被解开,一直是作为一条“批消息”来进行处理的`。
构建批消息和解开批消息分别在发送端和消费端的客户端完成,不仅减轻了 Broker 的压力,最重要的是减少了 Broker 处理请求的次数,提升了总体的处理能力。
使用顺序读写提升磁盘 IO 性能
顺序写和随机写的区别
顺序写就是只在文件末尾追加数据
利用 PageCache 加速消息读写
PageCache: 通俗地说,PageCache 就是操作系统在内存中给磁盘上的文件建立的缓存。无论我们使用什么语言编写的程序,在调用系统的 API 读写文件的时候,并不会直接去读写磁盘上的文件,应用程序实际操作的都是 PageCache,也就是文件在内存中缓存的副本
Page cache由内存中的物理page组成,其内容对应磁盘上的block。page cache的大小是动态变化的,可以扩大,也可以在内存不足时缩小。cache缓存的存储设备被称为后备存储(backing store),注意我们在block I/O一文中提到的:一个page通常包含多个block,这些block不一定是连续的。
读Cache
当内核发起一个读请求时(例如进程发起read()请求),首先会检查请求的数据是否缓存到了page cache中,如果有,那么直接从内存中读取,不需要访问磁盘,这被称为cache命中(cache hit)。如果cache中没有请求的数据,即cache未命中(cache miss),就必须从磁盘中读取数据。然后内核将读取的数据缓存到cache中,这样后续的读请求就可以命中cache了。page可以只缓存一个文件部分的内容,不需要把整个文件都缓存进来。
写Cache
当内核发起一个写请求时(例如进程发起write()请求),同样是直接往cache中写入,后备存储中的内容不会直接更新。内核会将被写入的page标记为dirty,并将其加入dirty list中。内核会周期性地将dirty list中的page写回到磁盘上,从而使磁盘上的数据和内存中缓存的数据一致。
那这个时候就会出现两种情况:
一种是 PageCache 中有数据,那就直接读取,这样就节省了从磁盘上读取数据的时间;
另一种情况是,PageCache 中没有数据,这时候操作系统会引发一个缺页中断,应用程序的读取线程会被阻塞,操作系统把数据从文件中复制到 PageCache 中,然后应用程序再从 PageCache 中继续把数据读出来,这时会真正读一次磁盘上的文件,这个读的过程就会比较慢。
零拷贝技术
我们知道,在服务端,处理消费的大致逻辑是这样的:
首先,从文件中找到消息数据,读到内存中
然后,把消息通过网络发给客户端。
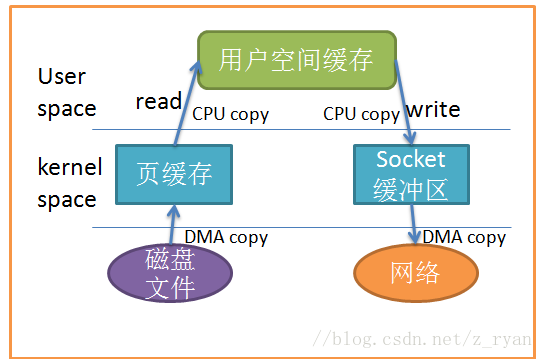
这个过程中,数据实际上做了 2 次或者 3 次复制:
从文件复制数据到 PageCache 中,如果命中 PageCache,这一步可以省掉;
从 PageCache 复制到应用程序的内存空间中,也就是我们可以操作的对象所在的内存;
从应用程序的内存空间复制到 Socket 的缓冲区,这个过程就是我们调用网络应用框架的 API 发送数据的过程。
Kafka 使用零拷贝技术可以把这个复制次数减少一次,上面的 2、3 步骤两次复制合并成一次复制。直接从 PageCache 中把数据复制到 Socket 缓冲区中,这样不仅减少一次数据复制,更重要的是,由于不用把数据复制到用户内存空间,`DMA` 控制器可以直接完成数据复制,不需要 CPU 参与,速度更快。
如果你遇到这种从文件读出数据后再通过网络发送出去的场景,并且这个过程中你不需要对这些数据进行处理,那一定要使用这个零拷贝的方法,可以有效地提升性能。
版权声明 本文属于本站 原创作品,文章版权归本站及作者所有,请尊重作者的创作成果,转载、引用自觉附上本文永久地址: http://blog.lujianxin.com/x/art/r6u3s7jxzkty
猜你喜欢
文章评论区
作者名片
- 作者昵称:Jeyrce.Lu
- 原创文章:61篇
- 转载文章:3篇
- 加入本站:2540天
作者其他文章

站长推荐
友情链接
站点信息
- 运行天数:2541天
- 累计访问:164169人次
- 今日访问:0人次
- 原创文章:69篇
- 转载文章:4篇
- 微信公众号:第一时间获取更新信息
